

2024年及以后 新型应用需要你刷新数据建模技巧查找你将面对的挑战和数据库设计模式
常说,正当你自认为知道所有答案时, 宇宙出现并改变所有问题数据库设计之全无例外正当你认为你拥有设计数据库所需的全部知识时, 新型应用似乎对数据库建模提出了新的挑战并必须适应以适应继续相关数据建模.
没有其他选择,只能不断获取新知识以免过时
好消息是您能继续使用数据库建模工具使用这些天-只要工具更新最新技术并允许你抽象数据模型,一例Vertabel.
文章中,我们会帮助你 指出如何数据库设计最佳做法自2024年起变化数据建模世界新手推荐你先查如何学习数据库设计阅读前
今日数据库设计模式
关系数据库仍在发展壮大上头entity-relational设计模式基础创建图代表实体和实体关系-仍然是设计关系数据库最常用方法
近些年来sql或非关系数据库获取关联性其主要美德是处理非结构化数据的可能性这使得它们独立于实体、属性和关系僵硬模式 典型关系模型上头文档模型存储数据到JSON或XML文档中模式为数据结构提供极大弹性,并典型地像MongoDB等NOSQL数据库
sql数据库设计模式为列模型,用列代替行作为数据存储单元这有助于检索子集数据比关系模型效率高得多数据库设计未来最佳实践中将包含并行和可扩缩性要求,
终于图模型sql数据库设计模式使用它表示数据间的复杂关系使用模式实例有数据模型分析欺诈(它必须分析大量交易之间的关系和关联)和数据模型社会网络Neo4j、OrientDB或亚马逊海王星等专用数据库管理程序用于实施图型模型
数据库设计趋势2024
进化应用架构和软件开发新趋势正与传统数据库设计模式的局限性相抗衡。大数据实时数据(RTD)是应用类型的两个实例,其具体需求迫使你重新思考创建模式的方式
可追踪性、数据质量、审核和编版等需求对大数据研发过程至关重要数据库设计趋势2024年将量身定制以满足这些需求清晰识别设计模式使用,让我们先研究这些过程不同阶段需要什么
数据库设计模式数据摄取
现代数据库架构内摄取层负责收集大数据并存储到统一存储库中,以便用于净化、处理和分析嵌入式数据存储器可采取多种形式,如数据湖、数据库和数据存储器这些存储库的主要需求是灵活消化非结构化信息,取自多源并使用变量格式
数据摄取模式实例是实时存储用户事件模式模式的优势在于它可扩展到数万同时使用者的水平而不遗漏任何事件模式特征为最小表数,中心表可存储信息而不设前缀结构
内实体关系图下示例显示事件中心表与事件类型、用户和设备查找表相关外加列录入信息本列可以是EXT、JSON或XML类型
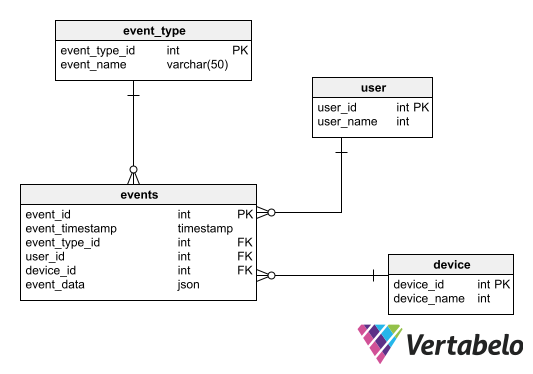
基本存储实时事件数据模式
视大数据存储库实施方式而定,数据摄取可能不是实时完成,而是批量完成遇此情形,需在批量中添加源标识事件处理台表保证数据可追踪性复制ERD像上例中的例子,查一查这篇文章如何从零画数据库模式.
数据库设计元数据模式
灵活性是数据摄取设计模式的优先级不幸的是,这带来了数据误差增加问题正因如此数据接收库必须经历清理验证阶段由此阶段产生,你应拥有一致性数据集并保证完整性数据集可编入现代数据库架构并预建结构
大数据存储库所存信息净化验证过程需要响应元数据模式的系统图解scheme提供参考,使净化验证过程知道摄取数据必须使用什么格式和它们必须遵守什么验证规则举例说,元数据模式可以表示原数据存储库中每个元素的数据类型、最长长度和强制性质元数据应反映最终数据库结构,清理验证数据最终归结
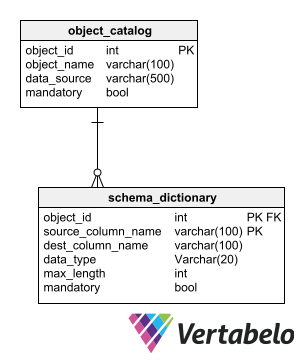
基本元数据编程存储规则 源信息大数据存储库
微服务
微服务架构已成为公司数字复兴的决定性因素因为它们允许单词应用划分为分解函数组件APIs.脱钩允许每个微服务根据其特殊需要独立缩放此外,微服务架构可封装功能和数据,提供潜在的故障隔离以避免单服务故障向同级传播
从数据持久性看,微服务采用基本模式称之database-per-service.按照此模式,数据库对每个微服务是私有的微服务需要信息存放于另一个数据库时,信息必须经由APIs提供为了避免频繁API调用管理费,使用不同服务间数据重复司空见惯,如下文所示。
实现数据库-服务模式最理想方式是每个服务都拥有自己的数据库服务器最大可用性-这是架构基本特征-微服务使用模拟数据库引擎(如Redis或Memcached)以最大限度地提高低容量数据库性能是常见的然而,这不是对微服务的要求彼此可使用不同的数据库引擎,即使彼此互连并属于同一系统的一部分。一种微服务可使用传统RDBMS记录正规模式中的事务,而另一种访问者则访问NOSQL数据库高容量分析查询
如上所述,不同的微服务系统不应共享集中数据库万一发生故障,则无法自由独立缩放并产生多点故障:如果单微服务故障击败中央数据库,使用该数据库的所有其他服务也将失效。
数项微服务因某种原因必须共享数据库时,必须有一种表分治形式,以确保每组表都属于特定服务不同分区表间不引用实现此模式之方法 — — 并减轻部分缺陷 — — 即为每个微服务分配不同的数据库用户并分配用户权限
下例中,四种微服务组成电子商务系统共享分治数据库四种微服务为:
- 产品目录
- 指令管理
- 验证和用户
- 购物车
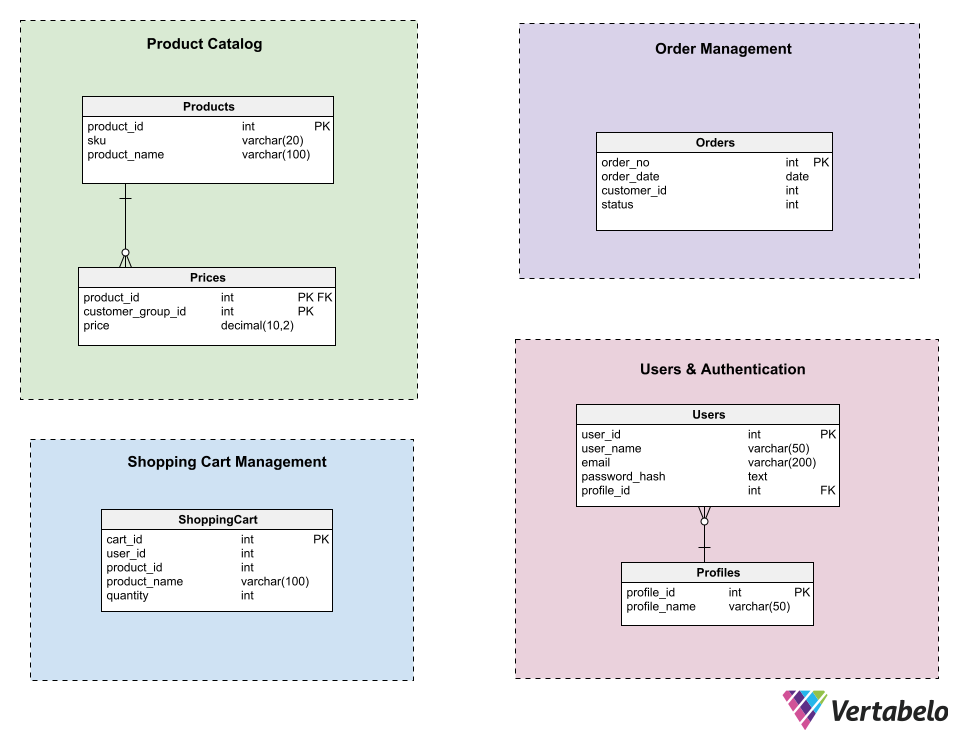
本图主题区为每个微服务设置数据模型边界维护微服务固有封装性时,不应有任何关系涉及属于不同主题领域的表
传统化数据库设计原理将诱导你在不同分区表间建立关系以确保优先完整性举个例子,你可能想建立外国密钥关系使用macduct_id中购物Cart并产品类表格-但数据库-服务模式无法实现以这种模式,可能还宜引入冗余性以尽量减少连续调用损耗服务性能API的必要性
上例中购物Cart表中包括macduct_name避免购物墨盒服务调用产品目录服务获取每种产品的名称检查这些其他数据库图示例可能有助于说明这些概念
缓存模式
REST(代理状态传输)API使用一套建筑约束,目的是优化网络服务性能、可扩展性与可修改性ERST架构风格中,数据和功能被视为资源并使用统一资源标识符访问REST架构常用缓存模式优化数据访问性能,利用Redis、Memcached或Hazelcast等模拟数据库技术高性能执行API数据缓存模式还有助于减少集中数据库的工作量
常用模式执行数据缓存键值数据库.键值数据库是一种数据存储法,它采取大表独有标识符的形式,每种标识符都与值相关联。配对被称为键值对键允许快速查找数据(如关系模型中的任何表),值可以是数据本身或数据定位
键值数据库可标为简单双列表
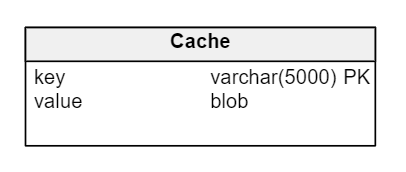
键值存储器结构可以像表两列一样简单注意列传值数据类型必须足够大并足够灵活以接受任何东西
实现缓存并减少读到集中数据库时,可实现模拟键值数据库执行数据缓存模式并代理主数据库数据库存储SQL查询为密钥并存储每次查询结果为值
可缩放性并行性
数据库设计模式多为2024竞赛最适配交付可缩和并行性,即新应用组的“holyGrails”。分栏数据库模式在用户偏爱方面表现突出,
列数据库固有设计提供并行和可扩缩性列数据库中表单列存储,列内所有值归并数据库系统如Snowflake或BigQuery执行列模式,数据按列存储,数据按列访问
列数据库带产品类表SKU和Price属性,所有SKU和所有物价都存储在一起允许优化阅读操作从属性子集取数据忽略别需要获取表内所有SKUs时,读取最优方式是不逐行遍历表
下示例比较产品类表传统表格格式和以列格式存储的相同数据
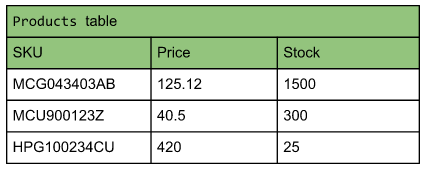
上头产品类数据存储列格式
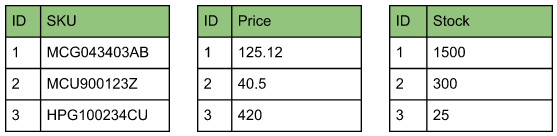
带列存储模式,表上新列可不影响现有列模式的另一特征是允许单列编译、压缩或分治,允许微量优化性能和存储空间
分布式数据仓库中,列数据库模式允许列级分治数据并行读操作并横向跨由多节点构成的弹性平台
底线是,不需要事先大小性能存储数据库存储数据可无限增长,简单为基础设施添加更多节点,不影响性能或效率
处理更改
整篇文章中,我们研究数据库设计2024年以后的主要趋势新名称和新思想数似乎压倒性但要记住 多数都只是数据库概念进化 数十年前开发
适应数据库设计宇宙强加给我们的新需求时,我们必须愿意走出舒适区 — — 留下我们已经掌握和欢迎的新技术,这些技术将塑造未来数年的数据建模
